- Как обеспечить надежный бэкап данных в Hadoop: практическое руководство для специалистов
- Важность бэкапа в системах Hadoop
- Основные типы резервных копий в Hadoop
- Инструменты и технологии для бэкапа Hadoop
- Apache Hadoop DistCp
- Hadoop Archiving (HAR)
- Решения сторонних разработчиков
- Практическая реализация бэкапа Hadoop
- Пошаговая инструкция по созданию резервной копии данных
- Пример использования DistCp для копирования данных
- Реставрация данных и проверка работоспособности бэкапов
- Общие рекомендации по организации системы резервного копирования в Hadoop
Как обеспечить надежный бэкап данных в Hadoop: практическое руководство для специалистов
В эпоху больших данных вопрос сохранности и восстановления информации становится одним из ключевых для любой организации․ Hadoop, как одна из самых популярных платформ для хранения и обработки больших объемов данных, требует особого подхода к резервному копированию․ В этой статье мы поделимся нашим многолетним опытом, расскажем о современных методиках и инструментах, которые помогают нам обеспечить безопасность данных в Hadoop-кластере․
Важность бэкапа в системах Hadoop
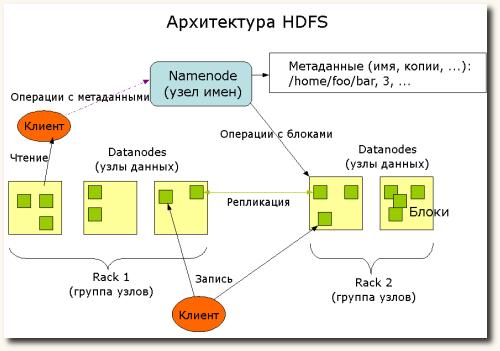
Hadoop – это масштабируемая платформа, которая строится на принципах распределенной обработки данных․ При этом она включает множество компонентов: HDFS, YARN, MapReduce, Hive, Spark и другие․ Потеря данных или их повреждение могут привести к катастрофическим последствиям для бизнеса․
Обеспечение надежных резервных копий данных – это не только способ защиты информации, но и важная часть стратегии бизнес-непрерывности․ Благодаря систематическому бэкапу мы можем легко восстановить данные и минимизировать время простоя, что критически важно в условиях высокой нагрузки и срочных требований к аналитике и отчетности․
Основные типы резервных копий в Hadoop
Перед тем как приступить к практическим рекомендациям, важно понять, какие виды бэкапов можно реализовать в контексте Hadoop-кластера:
- Полные бэкапы (Full Backups): копирование всей базы данных или файла всех данных и метаданных․
- Инкрементальные бэкапы (Incremental Backups): копирование только тех данных, которые были изменены после последнего полного или инкрементального бэкапа․
- Дифференциальные бэкапы (Differential Backups): копирование изменений после последнего полного бэкапа․
Выбор подходящего типа зависит от особенностей инфраструктуры, требований к скорости восстановления и уровня риска․ В большинстве случаев оптимальной стратегией является сочетание полного и инкрементального бэкапа․
Инструменты и технологии для бэкапа Hadoop
Для эффективного резервирования данных в Hadoop существует множество специализированных решений․ Рассмотрим наиболее популярные и проверенные временем инструменты․
Apache Hadoop DistCp
DistCp (Distributed Copy) – это инструмент, входящий в официальный комплект Hadoop, предназначенный для передачи данных между кластерами․ Он работает в режиме, использующем MapReduce, что делает его быстрым и масштабируемым․ Мы активно используем DistCp для создания резервных копий и перемещения данных между дата-центрами․
Hadoop Archiving (HAR)
Для хранения данных в архивных копиях удобно использовать формат HAR – он позволяет упаковать множество файлов в один архив и снизить нагрузку на файловую систему․
Решения сторонних разработчиков
Существуют готовые инструменты и платформы для автоматизации резервного копирования:
- Apache Falcon – для оркестровки процессов бэкапа и восстановления․
- Cloudera Manager и Hortonworks Data Platform – включают встроенные модули резервного копирования․
- Решения на базе сторонних платформ, такие как Veeam, CloudBerry, и другие, интегрируемые с Hadoop․
Практическая реализация бэкапа Hadoop
Пошаговая инструкция по созданию резервной копии данных
Теперь перейдем непосредственно к практическому руководству по выполнению бэкапа․ В нашей практике мы придерживаемся следующего алгоритма:
- Анализ данных и определение критичных элементов․ Перед началом важно понять, какие данные нужно сохранять в первую очередь: это могут быть данные HDFS, метаданные, конфигурационные файлы и т․д․
- Создание расписания бэкапа․ Определяем оптимальное время для выполнения копирования без влияния на производительность кластеров․
- Выбор методов копирования․ Например, для больших объемов – DistCp, а для резервных копий метаданных – использование встроенных инструментов․
- Настройка автоматизации процессов․ Автоматизированные скрипты и планировщики позволяют регулярно создавать резервные копии․
- Тестирование восстановления․ Обязательно проводим периодические тесты для убедительности, что данные можно восстановить без ошибок․
Пример использования DistCp для копирования данных
Рассмотрим пример команды для копирования данных между двумя кластерами Hadoop:
hadoop distcp
-source hdfs://cluster1/user/data/
-target hdfs://backup-cluster/user/data_backup/
Эта команда создаст полноценную копию данных, распределенных по кластеру cluster1, в удаленное хранилище backup-cluster․ Для обеспечения надежности стоит реализовать автоматизированные сценарии с логированием и оповещениями․
| Параметр | Описание | Пример | Рекомендуемое использование |
|---|---|---|---|
| -update | Обновление только измененных файлов | hadoop distcp -update ․․․ | Для инкрементальных копий |
| -delete | Удалять файлы в целевом месте, которых нет в исходнике | hadoop distcp -delete ․․․ | Для синхронизации полной копии |
| -m | Количество потоков для параллельной работы | hadoop distcp -m 16 ․․․ | Для ускорения процесса |
Реставрация данных и проверка работоспособности бэкапов
Процесс восстановления данных – не менее важный этап, чем создание резервных копий․ Он позволяет убедиться, что все созданные копии актуальны и готовы к применению в случае аварийного случая․
Для восстановления данных из DistCp или HAR архивов рекомендуется создавать отдельных сценариев и регулярно их тестировать․ Важным аспектом является своевременное обновление планов восстановления, их актуальность и наличие проверенных инструкций․
Обязательно после каждой процедуры бэкапа проводите тестовые восстановления, чтобы убедиться в целостности данных и их готовности к использованию․
Общие рекомендации по организации системы резервного копирования в Hadoop
- Регулярно обновляйте стратегии и планы резервного копирования в соответствии с изменениями инфраструктуры․
- Используйте автоматизацию и мониторинг для своевременного обнаружения ошибок или сбоев․
- Создавайте резервные копии не только данных, но и конфигурационных файлов для быстрого восстановления системы․
- Внедряйте многоуровневое резервное копирование, сочетающее полные и инкрементальные копии․
- Планируйте тестовые восстановительные процедуры и проводите их регулярно․
Обеспечение надежного бэкапа, это залог стабильной работы и безопасности вашей Hadoop-системы․ Внимательное планирование, использование проверенных инструментов и регулярное тестирование позволяют минимизировать риски потери данных и обеспечить быструю их восстановляемость․ Мы настоятельно рекомендуем внедрять систематические процедуры резервного копирования и постоянно совершенствовать подходы в соответствии с ростом объема данных и усложнением инфраструктуры․
Вопрос: Почему важно регулярно проводить тесты восстановления данных в Hadoop, и как правильно их организовать?
Ответ: Регулярные тесты восстановления данных необходимы для подтверждения эффективности резервных копий и уверенности в том, что в случае аварии вы сможете быстро и без ошибок восстановить информацию․ Организация тестов включает в себя подготовку сценариев восстановления, создание изолированной тестовой среды, выполнение восстановления и проверку целостности данных; Также важно вести документацию всех процедур и регулярно обновлять их по мере изменения инфраструктуры․
Подробнее
| Бэкап Hadoop | Резервное копирование в Hadoop | DistCp примеры | Восстановление данных Hadoop | Инструменты для резервного копирования Hadoop |
| Автоматизация бэкапа Hadoop | Стратегии резервного копирования Hadoop | Обзор Hadoop clusters backup | Лучшие методы восстановления Hadoop | Техническое обслуживание Hadoop |
| Обеспечение целостности данных Hadoop | Резервные копии метаданных Hadoop | Архивание данных Hadoop | Автоматическое восстановление Hadoop | Облачное хранилище Hadoop |
| Безопасность резервных копий Hadoop | Инстракты по резервному копированию | Обновление резервных копий Hadoop | Организация резервных копий | План восстановления Hadoop |