- Все‚ что нужно знать о бэкапе данных в среде Big Data (Hadoop): особенности‚ стратегии и лучшие практики
- Что такое Big Data и почему для нее важен бэкап?
- Определение Big Data
- Ригидность данных в больших системах
- Особенности архитектуры Hadoop и вызовы в резервном копировании
- Основные компоненты Hadoop и хранение данных
- Какие вызовы возникают при организации бэкапа в Hadoop?
- Стратегии бэкапа для системы Hadoop: что выбрать?
- Полное резервное копирование (Full Backup)
- Инкрементальный и дифференциальный бэкап
- Что из себя представляет эффективная стратегия бэкапа?
- Практические инструменты для бэкапа Hadoop
- Инструменты и решения
- Выбор подхода зависит от:
- Лучшие практики организации бэкапа данных в Hadoop
- Советы и рекомендации
- Типичные ошибки и их избегание
- Дополнительные ресурсы и материалы
Все‚ что нужно знать о бэкапе данных в среде Big Data (Hadoop): особенности‚ стратегии и лучшие практики
В современном мире объемы данных растут с невероятной скоростью. Компании и организации ежедневно генерируют терабайты‚ а порой и петабайты информации‚ и для успешного функционирования их систем необходимо не только активно собирать и обрабатывать эти данные‚ но и обеспечивать их сохранность. Одним из ключевых элементов такой гарантии является организация эффективных бэкап-стратегий.
В нашей статье мы подробно разберем‚ что такое бэкап данных в среде Big Data‚ особенно в контексте популярной платформы Hadoop‚ познакомимся с основными методами резервного копирования‚ рассмотрим особенности архитектуры и поделимся лучшими практиками‚ которые позволяют минимизировать риски потерь информации.
Что такое Big Data и почему для нее важен бэкап?
Определение Big Data
Термин «Big Data» объединяет огромные объемы структурированных и неструктурированных данных‚ которые невозможно эффективно обрабатывать с помощью традиционных методов хранения и аналитики. Основные характеристики Big Data — это объем‚ скорость обработки и разнообразие источников (часто именуемые как 3V, Volume‚ Velocity‚ Variety).
Ригидность данных в больших системах
Работа с такими данными требует специальных платформ и инструментов‚ таких как Hadoop‚ Spark‚ Kafka. Они позволяют не только хранить и анализировать‚ но и обеспечивать масштабируемое и отказоустойчивое хранение данных.
Почему важно создавать резервные копии данных в системах Big Data? — Потому что потеря данных‚ особенно в крупных информационных системах‚ может привести к серьезным сбоям в бизнес-процессах‚ потерям репутации и финансовым убыткам. В средах Hadoop отказоустойчивость достигается не только благодаря Hadoop-архитектуре‚ но и через надежные стратегии резервного копирования.
Особенности архитектуры Hadoop и вызовы в резервном копировании
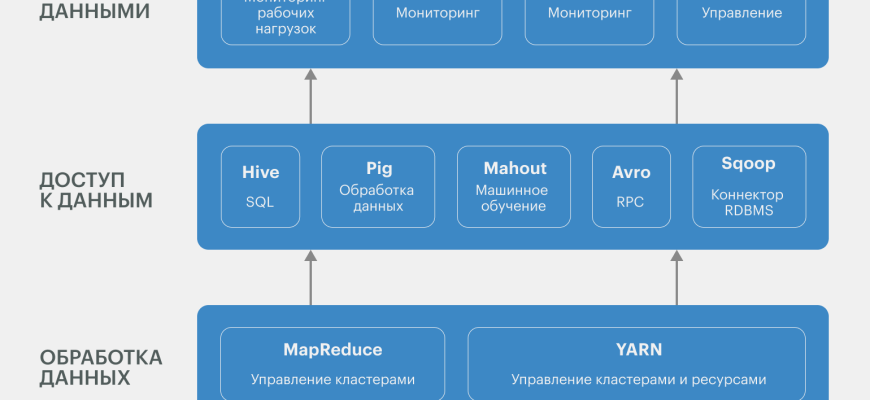
Основные компоненты Hadoop и хранение данных
Apache Hadoop включает несколько ключевых компонентов:
- HDFS (Hadoop Distributed File System), распределенная файловая система‚ которая разбивает файлы на блоки и хранит их на множестве узлов‚ обеспечивая отказоустойчивость и масштабируемость.
- YARN — платформа для управления ресурсами и выполнения задач.
- MapReduce — модель программирования для обработки больших данных.
Для хранения и резервного копирования данных важно понять‚ что HDFS управляет данными автоматически и способен обеспечить высокую доступность за счет репликации.
Какие вызовы возникают при организации бэкапа в Hadoop?
- Большие объемы данных — требуется эффективное решение для их копирования.
- Непрерывная обработка данных — бэкап не должен мешать работе систем.
- Распределенность инфраструктуры, данные хранятся на множестве узлов‚ и их восстановление должно быть централизованным и надежным.
- Сложность структур данных — не все данные хранятся в читаемом виде‚ а их восстановление должно сохранять целостность.
Стратегии бэкапа для системы Hadoop: что выбрать?
Полное резервное копирование (Full Backup)
Полное копирование всех данных — наиболее надежный и очевидный способ сохранить все содержимое системы. В Hadoop это обычно включает копирование всех данных HDFS и метаданных. Такой подход требует значительных ресурсов и времени‚ но обеспечивает максимальную надежность восстановления.
Инкрементальный и дифференциальный бэкап
Инкрементальные бэкапы позволяют копировать только изменения‚ произошедшие после последнего полного или инкрементального бэкапа. Это существенно снижает требования к ресурсам и времени.
Дифференциальный бэкап — копирует все изменения с момента последнего полного бэкапа. В ситуации с Hadoop это может быть реализовано через копирование только новых или измененных файлов или данных на определенные временные периоды.
Что из себя представляет эффективная стратегия бэкапа?
Идеальный подход заключается в сочетании различных методов:
- Регулярное полное копирование данных по графику (например‚ раз в неделю).
- Использование инкрементальных бэкапов для ежедневных изменений.
- Настройка автоматизированных процессов резервирования‚ чтобы минимизировать риск человеческой ошибки.
- Обеспечение хранения копий в нескольких географически разнесенных местах.
Практические инструменты для бэкапа Hadoop
Инструменты и решения
| Название | Описание | Плюсы | Минусы |
|---|---|---|---|
| DistCp | Инструмент для копирования больших объемов данных между кластерами Hadoop | Масштабируемость‚ автоматизация‚ высокая скорость | Требует настроек сети и прав доступа |
| HDFS snapshots | Механизм моментальных снимков файловой системы HDFS | Быстрое создание и восстановление‚ минимальные ресурсы | Ограничение на объем и частоту создания снимков |
| Apache Falcon | Инструмент автоматизации и оркестрации задач бэкапа и восстановления | Гибкость‚ автоматизация процессов | Требует сложной настройки и управления |
Выбор подхода зависит от:
- Объемов данных
- Требуемых сроков восстановления
- Бюджета и ресурсов
- Надежности сети и инфраструктуры
Лучшие практики организации бэкапа данных в Hadoop
Советы и рекомендации
- Автоматизация процессов — настройте автоматические расписания для регулярных копирований данных.
- Где хранить резервные копии — используйте репликацию и хранение в облаке или на отдельных серверах.
- Проверка целостности данных — регулярно тестируйте восстановление из резервных копий‚ чтобы убедиться в их работоспособности.
- Документирование процессов, ведите учет всех операций‚ чтобы быстро реагировать на сбои.
- Обучение команды — подготовьте специалистов‚ умеющих быстро восстанавливать данные.
Типичные ошибки и их избегание
- Недостаточная частота бэкапов, лучший способ потерять важные изменения.
- Отсутствие хранения копий в разных географических точках.
- Недостаточное тестирование восстановления — лучшие планы бессмысленны без проверки их практической реализации.
- Игнорирование обновлений инструментов и систем резервирования.
Обеспечение надежного бэкапа в среде Big Data‚ особенно в Hadoop‚ это не просто рекомендация‚ а обязательное условие стабильной работы и защиты от потерь. Надежные стратегии‚ современные инструменты и постоянное тестирование — вот залог того‚ что ваши данные всегда в безопасности. В конечном итоге‚ правильное управление бэкапами помогает сохранить не только информацию‚ но и доверие клиентов и успешность бизнеса.
Как обеспечить безопасность данных в Hadoop и почему это важно? — Потому что в эпоху Big Data потеря информации равносильна смерти бизнеса. Постоянный бэкап‚ автоматизация процессов и тестирование восстановления позволяют не только защищать данные‚ но и оперативно реагировать на любые сбои.
Дополнительные ресурсы и материалы
Подробнее
| стратегии резервного копирования Hadoop | инструменты бэкапа Hadoop | лучшие практики хранения данных | автоматизация резервных копий Hadoop | обновление и тестирование резервных копий |
| структура данных Hadoop | настройка DistCp | автоматизации бэкапа | разделение ответственного за резервирование | облачные решения для хранения резервных копий |